Informatie vanuit sales-data wordt vaak onvoldoende meegenomen om de productie efficiënter en effectiever te laten verlopen. Hierdoor blijven kansen liggen! Dat komt onder meer omdat we vaak te simplistisch naar verkoopinformatie kijken.
Kijk bijvoorbeeld naar de volgende twee verwachtingen:
We verwachten volgende maand een totale verkoop van product A van 5.000 Storage Keeping Units (SKU).
We verwachten volgende maand elke maandag een order van 800 SKU en 1 order tussendoor van 1.800 SKU.
De tweede verwachting geeft veel meer aanknopingspunten voor het inplannen van productiecapaciteit en het optimaliseren van de voorraad dan de eerste. Goede informatie over de verwachte (forecast) en geplande (demand) verkopen is dan ook zeer waardevol voor productieplanning.
Veelal wordt verkoopdata geaggregeerd tot een hoger niveau zodat deze makkelijker is om te interpreteren. Maar om effectief gebruik te kunnen maken van sales-data voor productieplanning is een extra verdieping nodig. Door de juiste verdieping wordt sales-data omgezet in relevante informatie om beter op te kunnen plannen.
In dit stuk gaan wij in op 3 manieren waarop je meer kunt halen uit jouw sales-data.
Het groeperen van sales-data
Het optimaliseren van voorraad versus productie
Het maken van een productieplanning
Hierbij starten we bij een hoog aggregatieniveau en duiken we steeds meer in detail.
Groeperen om werkcapaciteit en grondstoffen beter in te plannen
Statistieken op geaggregeerd niveau, zoals hoeveel verkopen wij van product A, kunnen zeker interessant zijn. Maar meerwaarde op dit niveau ontstaat vooral wanneer we producten op relevante kenmerken kunnen groeperen. Bijvoorbeeld, hoeveel producten gaan wij verkopen die allemaal dezelfde machineafstellingen nodig hebben? Of hoeveel verkoop verwachten we van producten die gebaseerd zijn op dezelfde grondstoffen? Hoe beter gegroepeerd kan worden op dergelijke kenmerken, hoe zekerder je kunt zijn van de waardes die eruit komen. Stel je verwacht bijvoorbeeld 50 stuks van product A1 of 30 stuks van product A2 te verkopen, en beiden maken gebruik van dezelfde grondstoffen. Dan is het vrij zeker dat je de gemeenschappelijke grondstoffen nodig zult hebben, en deze kun je dus alvast op voorraad zetten.
Praktisch kun je als volgt denken: wat is de kans op X verkopen van elk artikel? Deze getallen kun je vervolgens bij elkaar optellen. Zo kom je tot een verwachte waarde, die wanneer je meerdere kleinere producten kunt groeperen tot een redelijk betrouwbaar resultaat leiden. Let er wel op dat als je niet kunt groeperen voor enkele producten, deze producten altijd tussen wal en het schip zullen vallen. Als je 50% kans hebt om 10 te verkopen en je hebt grondstoffen voor 5, dan heb je immer te veel als er niets wordt verkocht en te weinig wanneer je wel verkoopt. Of je liever aan de veilige kant (hoger in voorraad en werkcapaciteit) of lagere kant zit is hierbij een afweging die jij alleen zelf kunt maken.
Effectief omgaan met wat er op voorraad komt
Wanneer we kijken naar voorraadoptimalisatie dan slaat dit op meerdere aspecten van het productieproces. Hoeveel grondstoffen hou je in voorraad, hoeveel halffabricaat staat op voorraad (indien relevant) en hoeveel eindproducten?
Bij voorraadvraagstukken kan op productniveau naar de totale aantallen die per product worden verkocht worden gekeken. Een dimensie die daarbij echter vaak wordt weggelaten is met welke kans en frequentie de verkoop zich voltrekt. Men kijkt vaak als volgt; van Product A hebben wij in september 50 SKU verkocht. Meer aanknopingspunten kunnen ontstaan wanneer bekend is dat dit bestaat uit 10 orders van 5 verkopen. Er zit namelijk een belangrijk verschil tussen 10 verkopen van 5 SKU of 1 verkoop van 50 SKU. Deze laatste verkoop kun je immers niet realiseren met 30 SKU op voorraad. Maar met deze voorraad kunnen wel de eerste 6 verkopen van 5 SKU worden uitgeleverd. Dit is een gebied waar in sales-data vaak niet naar gekeken wordt, maar dat is totaal onterecht!
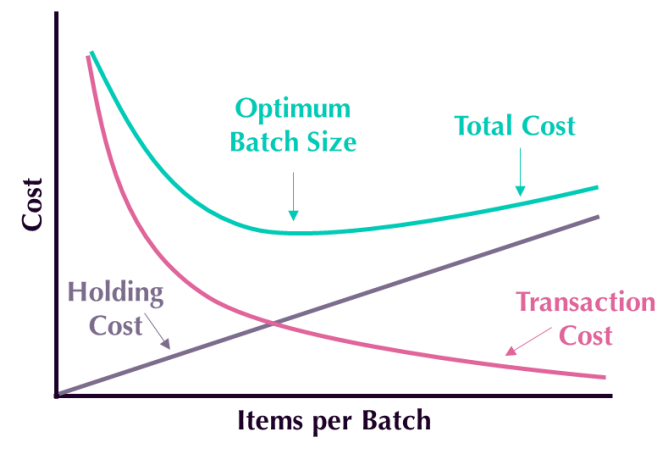
Bij het optimaliseren van batchgroottes is namelijk de U-curve optimalisatie (The Principles of Product Development Flow 2009, Donald G. Reinertsen) van toepassing. Het bepalen van de optimale batchgrootte is feitelijk een afweging van opstartkosten en voorraadkosten. Denk ter vergelijk aan het kopen van eieren in de supermarkt. Haal jij iedere keer 1 ei en wil je dagelijks een eitje maken, dan moet je vaak heen en weer naar de supermarkt. Haal je echter 365 eieren in 1x dan zit je met een huis vol eieren die gekoeld moeten worden. Je hoeft maar 1x per jaar naar de supermarkt wat tijd en brandstof bespaard, maar je hebt wel extra ruimte in je huis, een koelkast en extra energie nodig. Beiden benaderingen zijn dus niet optimaal. Je wilt dus ergens in het midden zitten(link naar youtube).
Bij de U-curve optimalisatie worden opstartkosten (transaction cost) gepresenteerd als omgekeerd evenredig (eenmalige kosten / aantal SKU) en voorraadkosten (holding cost) als evenredig gepresenteerd (elke SKU kost iets in voorraad) gezien. De voorbeeldgrafiek laat zien dat er een optimale batchgrootte (optimum batch size) berekend kan worden.